


Comment créer une IA en 2024 : Le guide complet (+ idées d’IA)
Dernière date de mise à jour le : 11 septembre 2024 à 05:42 pm
 5,00/5
5,00/5Points-clés
- Les types d’IA : Leurs différences résident principalement dans le niveau de généralité et d’autonomie.
- Les types de machine learning : Leurs différences se situent dans la nature des données utilisées et dans les méthodes d’apprentissage.
- Outil no code : Plateforme ou logiciel qui permet aux utilisateurs de développer des modèles d’IA sans nécessiter de compétences en programmation avancées.
- Les phases de création d’une IA : Fixer l’objectif du projet, recueillir et préparer les données, choisir le bon algorithme, entraîner et évaluer le modèle, déployer dans un environnement opérationnel.
- Exemples de cas d’utilisation d’IA : Personnaliser l’expérience client, anticiper les comportements des consommateurs, optimiser les campagnes publicitaires et automatiser le service client.
L’intelligence artificielle (IA) est une technologie capable d’imiter l’intelligence humaine, programmée pour apprendre à partir de données, à raisonner et à résoudre des problèmes. Dans le domaine du marketing, on l’utilise pour automatiser des tâches, analyser des données et prendre des décisions. Vous souhaitez savoir comment créer une IA sans nécessairement recourir à un langage de programmation ? À travers la lecture de cet article, plongez au cœur des différentes étapes qui vous aideront à concevoir un outil innovant et performant.
Comprendre les bases de l’IA
Types d’IA
Les différents types d’intelligence artificielle (IA) sont généralement classés en fonction de leurs capacités et de leurs méthodes de fonctionnement.
IA faible (ou étroite)
L’intelligence artificielle faible, aussi appelée intelligence artificielle étroite, se réfère à des systèmes d’IA conçus pour effectuer des tâches précises ou résoudre des problèmes limités dans un domaine particulier. Elle ne peut donc pas généraliser ses compétences pour s’adapter à de nouveaux domaines ou contextes.
Découvrez combien coûterait votre projet avec un rapport budgétaire personnalisé

Les systèmes d’IA faible s’utilisent souvent dans diverses applications telles que :
- La reconnaissance vocale
- La reconnaissance d’images
- Les systèmes de recommandation
- Le traitement automatique du langage naturel
- Les véhicules autonomes
- Etc.
En outre, ils sont entraînés sur des ensembles de données spécifiques et ne peuvent pas extrapoler leurs connaissances au-delà de ces données. Cela signifie que les IA faibles ne sont pas capables de reproduire la polyvalence et la flexibilité du cerveau humain. En tout cas, elles restent largement utilisées dans de nombreux secteurs pour améliorer l’efficacité opérationnelle et fournir des solutions innovantes à divers problèmes.
IA forte (ou générale)
L’intelligence artificielle forte ou intelligence artificielle générale (IAG) est un concept hypothétique d’une machine capable de reproduire l’intelligence humaine dans son intégralité et de manière autonome.
Contrairement à l’IA faible, celle-ci serait à même d’appliquer son intelligence à de nouveaux domaines et de s’adapter à différentes situations sans intervention humaine. Elle serait dotée de conscience de soi, comme un être humain, en utilisant la logique et le bon sens. Toutefois, bien que ce type d’IA demeure largement théorique et n’ait pas encore été pleinement réalisée, elle suscite un grand intérêt et des débats dans la communauté scientifique et technologique en raison de son potentiel révolutionnaire.
La création d’une IA forte poserait des défis à la fois techniques et éthiques. Pourtant, elle pourrait également ouvrir la voie à de nombreuses possibilités, comme la résolution de problèmes complexes, la découverte de nouvelles connaissances, la création de nouvelles formes de collaboration entre l’homme et la machine, etc.

Machine learning
Le machine learning (apprentissage automatique) constitue une sous-discipline de l’IA qui se concentre sur le développement de pratiques permettant aux ordinateurs d’apprendre à partir de données et de réaliser des tâches sans programmation.
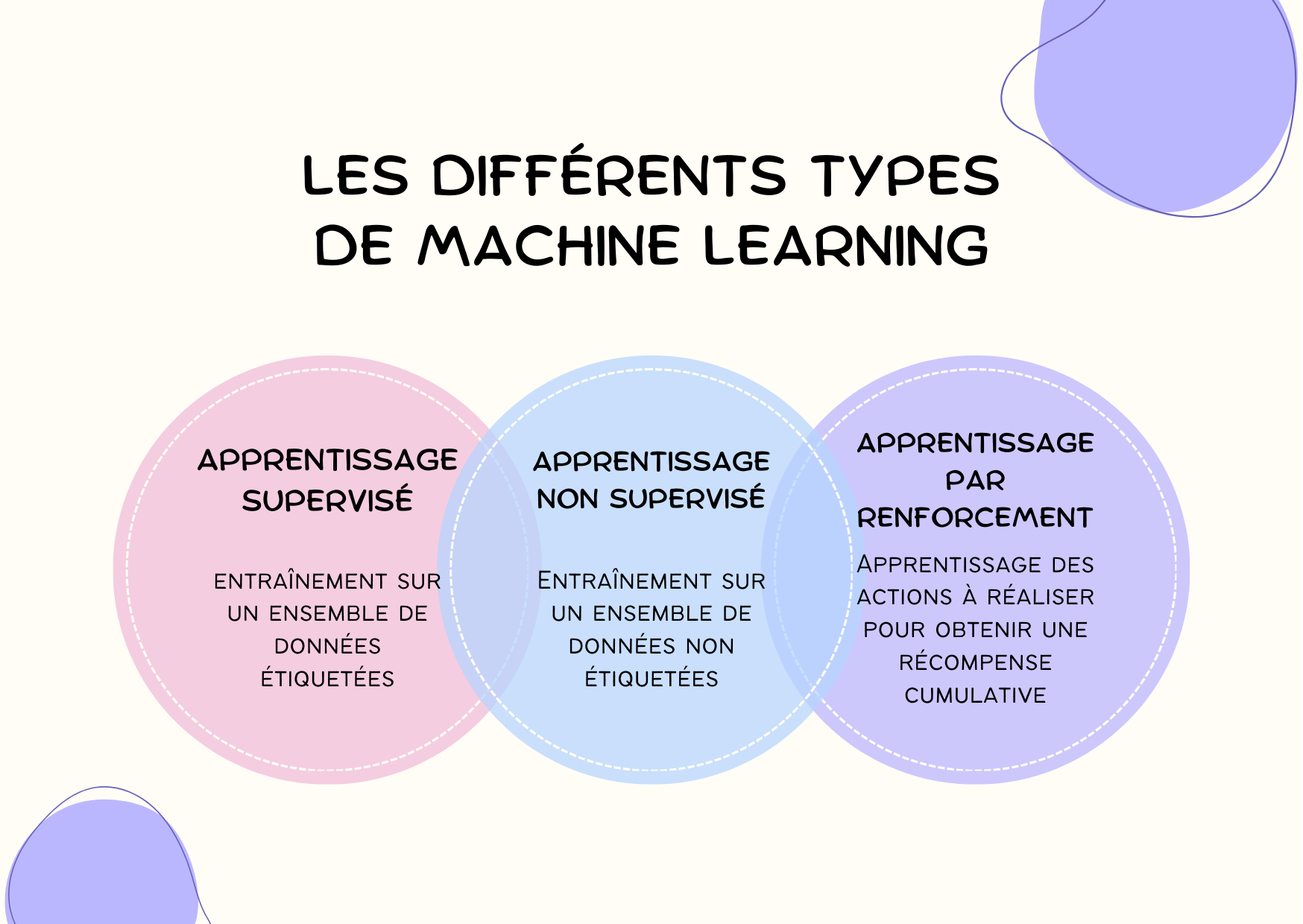
Apprentissage supervisé
Il s’agit d’un des principaux types de machine learning, où le modèle est entraîné sur un ensemble de données étiquetées. L’ensemble de données contient des exemples d’entrées et de sorties souhaitées, et le modèle apprend à prédire la sortie pour une nouvelle entrée. Les algorithmes courants incluent :
- La régression linéaire
- Les arbres de décision
- Les machines à vecteurs de support (SVM)
- Les réseaux de neurones.
L’objectif de l’apprentissage supervisé concerne le développement d’un modèle qui peut généraliser et faire des prédictions exactes sur des données non vues. Dans cette variante du machine learning, on retrouve deux types de tâches :
- La classification : le modèle apprend à prédire la catégorie à laquelle appartient une nouvelle entrée. Par exemple, on l’entraîne à prédire si un e-mail est spam ou non-spam.
- La régression : le modèle apprend à prédire une valeur numérique pour une nouvelle entrée. Il peut par exemple connaître à l’avance le prix d’une maison selon ses caractéristiques.
À noter que l’apprentissage supervisé nécessite des données étiquetées de haute qualité pour l’entraînement. La qualité de ces dernières a un impact significatif sur les performances de l’IA.
Apprentissage non supervisé
L’apprentissage non supervisé est un autre type de machine learning où le modèle est entraîné sur un ensemble de données non étiquetées, c’est-à-dire des données pour lesquelles les réponses désirées ne sont pas connues à l’avance. Il a été conçu pour découvrir des structures intrinsèques ou des modèles sous-jacents dans les données sans aucune guidance externe.
Ci-après les différentes méthodes d’apprentissage non supervisé :
- Clustering : il vise à regrouper les données similaires dans des clusters ou des groupes homogènes. Les algorithmes de clustering (K-means, clustering hiérarchique et DBSCAN) tentent de maximiser la similarité intracluster en minimisant la similarité intercluster.
- Réduction de dimensionnalité : elle se résume à réduire le nombre de variables ou de dimensions dans un ensemble de données tout en préservant au mieux les informations. Son but est de simplifier la représentation des données tout en limitant la perte d’informations.
- Détection d’anomalies : elle cherche à identifier les observations qui sont atypiques ou anormales par rapport au reste des données. On l’emploie souvent dans des domaines tels que la détection de fraude, la maintenance prédictive et la surveillance des systèmes.
Apprentissage par renforcement
Dans cette déclinaison du machine learning, l’agent (robot ou programme informatique) apprend à prendre des décisions à travers l’interaction avec son environnement. Son objectif ici consiste à maximiser une récompense cumulative dans un environnement donné.
Pour cela, l’agent a essentiellement recours à des stratégies d’exploration (essayer de nouvelles actions pour découvrir de meilleures récompenses) et d’exploitation (choisir les actions qui ont donné les meilleures récompenses dans le passé).
Par ailleurs, l’agent prend des décisions suivant son état actuel et sa politique. Ainsi, le processus d’apprentissage par renforcement comprend plusieurs éléments :
- L’environnement : contexte dans lequel l’agent opère et interagit (ex : jeux, simulations, robots physiques, etc.)
- L’état : situation ou configuration dans laquelle se trouve l’agent à un moment donné
- L’action : décisions prises par l’agent pour influencer son environnement
- La récompense : signal de feedback reçu de l’environnement par l’agent, indiquant si l’action prise était bonne ou mauvaise
- La politique : stratégie utilisée par l’agent pour choisir ses actions par rapport à son état actuel.
Étapes pour créer une IA
Il existe un bon nombre d’outils no code que vous pouvez utiliser pour créer votre propre IA. Parmi la liste, il y a Microsoft Lobe, OpenAI, Jasper, Copy.ai, ActiveCampaign, Bubble et Chatfuel. Ils offrent une manière accessible et conviviale de concevoir des applications d’intelligence artificielle pour une variété de cas d’utilisation, même sans compétences en programmation avancées.
Définir l’objectif
La première étape pour créer une IA consiste à déterminer le ou les objectifs du projet. En effet, une intelligence artificielle doit forcément répondre à un besoin avant d’être développée. Vous devez alors identifier le problème ou le défi auquel la solution va tenter d’apporter une réponse.
Ces objectifs doivent être mesurables et peuvent inclure des métriques de performance, des améliorations opérationnelles, etc. En parallèle, veillez à analyser les exigences et les contraintes qui influenceront la conception et le développement de l’intelligence artificielle. On peut par exemple citer les contraintes budgétaires, les exigences de sécurité, les contraintes matérielles ou logicielles, etc.
Ensuite, il convient de définir le champ d’application de votre projet d’intelligence artificielle. Concrètement, établissez les domaines sur lesquels vous souhaitez vous concentrer et les limites de votre système (restrictions d’utilisation, limites fonctionnelles…). Pour terminer, fixez les critères qui conditionneront le succès de votre système d’IA, à l’instar des objectifs de performance spécifiques et des niveaux de qualité à atteindre.
Cette première étape s’avère indispensable pour mettre en place une base solide et orienter le reste du processus de création. Elle garantit particulièrement la satisfaction des exigences de votre entreprise et la réalisation de vos objectifs commerciaux.
Collecte et préparation des données
Sélection des données pertinentes
Dans un premier temps, commencez par définir les caractéristiques et les attributs des données utiles à la résolution de votre problème d’IA. Vous pouvez utiliser des techniques telles que l’analyse exploratoire des données (EDA) pour comprendre la relation entre différentes variables et connaître celles qui ont le plus d’impact. La sélection de données pertinentes peut contribuer non seulement à réduire la dimensionnalité, mais aussi à améliorer les performances de l’intelligence artificielle et à réduire le temps de formation.
Nettoyage des données
Dans un second temps, il importe de nettoyer et prétraiter les données avant de les utiliser pour l’entraînement du modèle. Pour ce faire, nous vous recommandons de :
- Utiliser des méthodes statistiques et des visualisations afin de détecter les erreurs et les valeurs aberrantes. Celles-ci peuvent fausser les résultats du modèle, d’où l’importance de savoir si elles nécessitent une correction ou une suppression.
- Gérer les valeurs manquantes via l’imputation (moyenne, médiane, etc.) ou la prédiction (à l’aide de programmes d’apprentissage automatique).
- Supprimer les doublons pour éviter toute redondance et garantir des résultats cohérents.
- Encoder les variables catégorielles en variables numériques pour les rendre utilisables par les algorithmes d’apprentissage automatique.
- Corriger les incohérences et uniformiser les formats.
De cette manière, votre programme pourra être formé sur des données d’excellente qualité.
Choix de l’algorithme approprié
Dans un système d’IA, les algorithmes composant le réseau de neurones artificiels s’exécutent pour convertir une donnée entrante en une donnée sortante. Pour bien choisir ces algorithmes, il faut prendre en compte plusieurs facteurs, dont la nature des données, la complexité du problème et les ressources informatiques disponibles. Ci-dessous, découvrez les trois algorithmes couramment utilisés.
Réseaux de neurones
Les réseaux de neurones font référence à des modèles d’apprentissage profond inspirés du fonctionnement du cerveau humain. Ceux-ci se composent de couches de neurones interconnectés qui traitent et transmettent des informations entre eux. Les connexions entre ces neurones sont pondérées par des valeurs numériques appelées « poids ».
Les biais, quant à eux, correspondent aux valeurs constantes ajoutées aux signaux avant d’être transmis à la fonction d’activation. Cette dernière détermine la sortie d’un neurone en fonction de ses entrées.
En principe, on utilise les réseaux de neurones pour la classification, la régression, la détection d’objets et la génération de texte. Parmi les architectures populaires, on distingue :
- Les réseaux de neurones convolutionnels (CNN) pour la vision par ordinateur
- Les réseaux de neurones récurrents (RNN) pour le traitement du langage naturel
- Les réseaux de neurones entièrement connectés pour des tâches plus générales.
Arbres de décision
Les arbres de décision font partie des modèles d’apprentissage supervisé qui se servent d’une structure arborescente pour représenter et classer les données compte tenu des règles de décision. Chaque nœud de l’arbre représente une caractéristique des informations, et chaque branche représente une décision basée sur cette caractéristique.
Les arbres de décision sont faciles à interpréter et à visualiser. C’est pourquoi ils sont très prisés pour des tâches où l’interprétabilité est importante. En outre, il existe certaines techniques comme les forêts aléatoires et les arbres de décision boostés (XGBoost, LightGBM, etc.) pour améliorer les performances des arbres de décision de base.
Support Vector Machines (SVM)
Les SVM désignent des algorithmes d’apprentissage supervisé exploités pour les tâches de classification et de régression. Dans le premier cas, elles visent à créer une frontière (appelée hyperplan) qui sépare de façon optimale les données en différentes catégories. Dans le second cas, elles cherchent à prédire une valeur continue en apprenant à partir d’exemples étiquetés.
L’avantage principal des SVM est qu’elles se révèlent particulièrement efficaces pour les problèmes de classification avec des données complexes, notamment lorsqu’il y a un nombre limité d’échantillons. D’ailleurs, ces machines à vecteurs de support peuvent utiliser différentes fonctions de noyau pour manipuler des données non linéairement séparables. Et ce, en les transformant dans un espace de dimension supérieure.
Néanmoins, les SVM sont sensibles aux valeurs aberrantes et nécessitent parfois un réglage des hyperparamètres pour obtenir de bonnes performances. Quoi qu’il en soit, elles forment un outil d’apprentissage automatique polyvalent et puissant.
Entraînement du modèle
Une fois l’algorithme choisi, la prochaine étape consiste à l’entraîner pour qu’il puisse effectuer une tâche spécifique. Ce processus rassemble un bon nombre de démarches qui débutent par l’initialisation des paramètres de l’IA avec des valeurs initiales. Cela peut impliquer une initialisation aléatoire des poids ou des valeurs par défaut prédéfinies.
Puis, passez les données d’entraînement dans le modèle pour obtenir les prédictions. Chaque exemple d’entraînement est propagé à travers le réseau, et les sorties sont calculées à l’aide des poids actuels.
Pour calculer la perte, comparez les prédictions aux étiquettes réelles des données d’entraînement en utilisant une fonction de perte appropriée. Cette fonction mesure l’écart entre les prédictions du modèle et les vérités terrain. Autrement dit, elle représente la performance du modèle sur les données d’entraînement. Et pour ajuster progressivement les paramètres du modèle, l’utilisation d’un algorithme d’optimisation tel que la descente de gradient est de mise.
Ces différentes actions sont répétées sur plusieurs itérations jusqu’à ce que l’intelligence artificielle atteigne un niveau de performance satisfaisant sur les données d’entraînement et de validation.
Découvrez combien coûterait votre projet avec un rapport budgétaire personnalisé
Évaluation du modèle
Après avoir entraîné le modèle, il est temps d’évaluer sa performance sur des données indépendantes afin de mesurer son efficacité et sa capacité à généraliser sur de nouvelles données. Cette évaluation permet de déterminer si le système répond aux critères de succès définis au début du projet.
Au cours de cette étape, vous avez à disposition différentes métriques, dont le choix dépendra en partie du type de problème et de l’objectif de l’IA :
- Précision : proportion de prédictions correctes
- Rappel : proportion d’exemples positifs correctement identifiés
- F1-score : moyenne harmonique de la précision et du rappel
- Courbe ROC et AUC : évaluation de la capacité du modèle à distinguer les classes positives et négatives.
À l’issue de l’évaluation, vous avez encore la possibilité de procéder à des ajustements si nécessaire. Tout comme l’entraînement, ce processus peut être répété jusqu’à l’obtention de performances satisfaisantes.
Mise en production
La mise en production concerne la phase où l’intelligence artificielle est déployée dans un environnement opérationnel ou réel pour effectuer des prédictions ou des actions en temps réel.
Cette étape implique plusieurs opérations, à savoir :
- Le développement d’API ou d’interfaces utilisateur : pour permettre l’intégration de l’IA dans les systèmes existants
- La conception d’une infrastructure robuste et évolutive : pour supporter le modèle en production
- La mise en place de mécanismes de surveillance et de suivi : pour surveiller les performances de l’IA en temps réel et détecter les éventuels dysfonctionnements.
Le déploiement en production nécessite habituellement une collaboration étroite entre les équipes de développement, d’exploitation et de maintenance. C’est une garantie pour le bon fonctionnement et la disponibilité continue du modèle dans un environnement opérationnel.
Suivi et optimisation continue
Pour finaliser la création de votre IA, vous devez effectuer un suivi régulier de ses performances et collecter les informations sur son utilisation dans des conditions réelles. Vous pouvez employer des outils de visualisation pour explorer les données. Cette rétroaction est ensuite utilisée pour itérer sur l’IA en apportant des ajustements et des mises à jour pour améliorer ses performances au fil du temps.
Selon le besoin, vous pouvez être amené à ajouter de nouvelles fonctionnalités, à corriger des erreurs détectées, à optimiser des hyperparamètres ou même à remplacer complètement le modèle par une version plus avancée. Dans tous les cas, en adoptant une approche itérative et en s’engageant dans une amélioration continue, les entreprises peuvent mettre en place un système d’IA efficace et performant.

Défis et considérations éthiques
Confidentialité des données
L’intelligence artificielle soulève de nombreux défis et questions éthiques importants qu’il convient de considérer lors de son développement et de son exploitation. Parmi eux se trouve la confidentialité des données.
Il faut savoir que les systèmes d’IA exigent souvent l’accès à de grandes quantités de données pouvant contenir des informations sensibles sur les individus. Il paraît donc judicieux de protéger la confidentialité de ces données pour éviter toute violation de la vie privée. Dans cette optique, mettez en place des mesures de sécurité robustes afin d’éviter les accès non autorisés, ainsi que des politiques strictes de gestion et de partage des données pour garantir que seules les personnes autorisées y ont accès.
Des pratiques telles que l’anonymisation, la pseudonymisation et le chiffrement peuvent être utilisées pour conserver la confidentialité des données tout au long du processus de collecte, de stockage et d’utilisation.
Biais algorithmique
Le biais algorithmique est un autre défi majeur en matière d’éthique dans l’IA. De fait, les modèles d’intelligence artificielle peuvent reproduire et amplifier les biais présents dans les données d’entraînement. Ce qui est susceptible d’engendrer des résultats injustes ou discriminatoires pour certains groupes de population.
Par exemple, si les données d’entraînement sont biaisées en faveur d’un groupe particulier, le modèle peut favoriser ce groupe au détriment d’autres. Pour atténuer ce problème, il est essentiel de réaliser des audits réguliers des données en vue d’identifier et de corriger les biais potentiels. Les méthodes de débiaisage et d’équité s’avèrent d’une grande utilité pour concevoir des programmes qui produisent des résultats justes et équitables pour tous.
Transparence et explicabilité
Les décisions prises par une intelligence artificielle peuvent avoir un impact considérable sur la vie des utilisateurs. À cet égard, elles doivent être transparentes et explicables. Cependant, de nombreux modèles d’IA, en particulier ceux basés sur l’apprentissage profond, sont parfois considérés comme des boîtes noires. Ce qui signifie qu’il est difficile de comprendre comment ils prennent leurs décisions.
Pour résoudre ce problème, développez des stratégies d’interprétabilité qui permettent aux utilisateurs de connaître les raisons des décisions prises par les modèles. En voici quelques-unes :
- La visualisation des activations des neurones
- L’importance des fonctionnalités
- La génération d’explications textuelles pour les prédictions du modèle.
En suivant ces directives, les visiteurs auront plus confiance dans les décisions de votre IA et seront en mesure de corriger les erreurs ou les biais potentiels.
Idées de création d’IA en marketing
Personnalisation de l’expérience client
L’IA offre un potentiel immense pour la personnalisation de l’expérience client. Grâce à l’analyse des données clients et l’utilisation des algorithmes d’apprentissage automatique, vous pouvez facilement proposer des interactions engageantes.
Dans les détails, créer une intelligence artificielle vous donne l’opportunité de personnaliser les communications marketing, les offres de produits, les recommandations de contenu et même l’expérience sur un site web ou une application mobile.
Votre entreprise peut par exemple envoyer des e-mails personnalisés recommandant un service basé sur les achats précédents d’un client, ou afficher des offres spéciales qui correspondent aux intérêts démontrés par un client lors de ses visites précédentes sur le site web. Les avantages de l’utilisation de l’IA sont dans ce cas multiples, pour ne citer que le renforcement de la fidélité à la marque et l’augmentation du taux de transformation.
Analyse prédictive du comportement des consommateurs
L’IA peut être utilisée pour faire une analyse prédictive du comportement humain en anticipant les actions et les préférences des clients. D’une manière générale, cela se fait grâce à l’exploitation de leurs historiques, comme les achats précédents, les interactions sur les réseaux sociaux, les clics sur les sites web, etc.
Les achats futurs, les préférences de produits et les réactions aux offres promotionnelles sont autant de comportements clients que les modèles d’IA peuvent prédire. Au bout du compte, cette information permet à tout expert du marketing de personnaliser ses stratégies et de proposer des offres ciblées. De quoi améliorer l’engagement client et le taux de conversion.
Optimisation des campagnes publicitaires
En tant qu’entreprise, vous pouvez faire appel à l’intelligence artificielle pour améliorer la pertinence et l’efficacité de vos campagnes publicitaires sur Internet. Dans les faits, les algorithmes d’IA analysent en temps réel les données des utilisateurs pour cibler les annonces de manière plus précise. Cela concerne notamment :
- Le comportement de navigation
- Les interactions sur les réseaux sociaux
- Les recherches en ligne.
D’un autre côté, ces algorithmes servent à optimiser les enchères publicitaires en ajustant automatiquement les offres selon la probabilité de conversion de chaque utilisateur. Les marketers obtiendront ainsi un meilleur retour sur investissement (ROI) de leurs campagnes publicitaires en ligne, en maximisant la visibilité et en ciblant les audiences les plus pertinentes pour leurs produits ou services.
Chatbots et assistance clientèle automatisée
Le chatbot alimenté par l’IA est devenu un outil incontournable dans le secteur du marketing pour fournir une assistance client automatisée et personnalisée. Ce type d’agent conversationnel est capable de :
- Répondre aux questions des clients
- Apporter des recommandations de produits
- Qualifier les prospects et planifier des rendez-vous
- Effectuer des transactions, le tout en temps réel et de manière efficace.
Les chatbots utilisent essentiellement le traitement automatique du langage naturel (NLP) pour comprendre les demandes des internautes et répondre de manière efficace. Ils permettent aux entreprises de proposer un service client 24/7, d’améliorer l’expérience utilisateur et de réduire les coûts opérationnels liés à l’assistance client.
Conclusion
En somme, la conception d’une intelligence artificielle passe par plusieurs étapes. Il faut avant tout définir les objectifs du projet, puis collecter et nettoyer les données afin d’assurer la qualité des données d’entraînement du modèle. Une fois ce dernier entraîné, il est déployé en production, suivi d’une itération continue pour surveiller ses performances et apporter des ajustements au besoin.
L’avenir de l’IA dans le domaine du marketing est prometteur et en constante évolution. Avec l’essor de nouvelles technologies d’IA, les spécialistes du marketing pourront disposer de plus d’outils et de capacités pour interagir intelligemment avec leurs clients.


